昨天了解到了機器學習的各種學習方式,今天就要針對模型的目標來區分出兩種不一樣的問題,一個是回歸問題 ( Regression Problem ),一個是分類問題 ( Classification Problem ),回歸問題和分類問題都是基於監督式學習,這兩種問題下的模型,目的都是為了能夠根據標籤資料去做準確的預測,但兩種模型的差異就是它們如何被應用在不同的問題上,回歸問題下的模型目的是為了去預測一個連續的數值,像是預測薪水、年齡、體重等,而分類問題下的模型是為了能夠預測或者將離散的數值分類,能夠把傳入的資料區分為對應的不同類別 ( 分類 )。
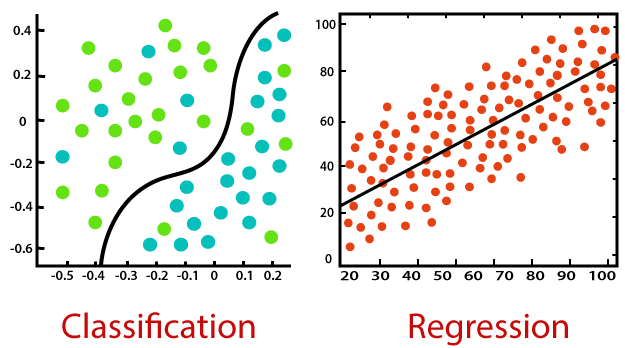
經由上兩圖可以發現到,圖中每個點皆為輸入至模型的資料,即為資料點,上圖右的回歸模型會根據這些資料點去做擬和,也就是回歸模型的輸出 ( 黑色斜線 ) 會盡量和資料點接近以縮小模型預測的誤差,至於上圖左的分類模型,就是為了讓模型的輸出能夠完美的把顏色不同的兩類,其資料點給區分開來 ( 分類 )。
通常用來做回歸問題的模型 ( 回歸模型 ),這個模型最終會預測出一個連續數值,在統計學中,所謂連續數值就是在一定區間內可以任意取值,其數值是連續不間斷的,相鄰的兩數可以做無限的分割,像是我們平時測量的身高,因為身高 170 ~ 171 ( cm ) 之間存在小數,能夠有無限多個數值,有可能為 170.1、170.01、170.001 等,因此身高也為連續數值的一種,其他的還有體重 ( 56.5 kg )、房價 ( EX : 18.5 萬 )、筆的長度 ( 15.2 cm ) 等只能透過測量或計算得到的數值,而我們通稱這些數值為一個純量 ( Scalar )。
在回歸問題中可以想成其目的就是要讓模型最後輸出的結果會是一個數值 ( Scalar ),輸入一些資訊,根據這些資訊輸出一個數值,下面是回歸問題應用到各個領域的情況 :
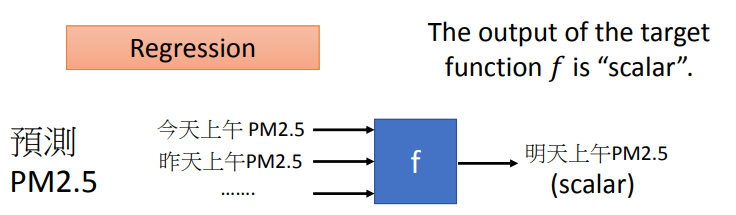
要讓模型對未來的時間做出 PM2.5 的預測,就必須給它訓練資料,這個些訓練資料包含的可能是前幾天的資訊或者是過去所蒐集的資料,做為模型的輸入,最後再輸出一個數值 ( Scalar ) 作為模型的輸出預測。

Stock Market Forecast 股票市場預測
輸入 : 過去股票市場起伏的資料,輸出 : 道瓊指數
Self-driving Car 無人自走車
輸入 : 路上看到的影像畫面,輸出 : 方向盤的角度

推薦系統 Recommendation
輸入 : 使用者 A 和 商品 B,輸出 : 使用者購買此商品的可能性

根據不同的模型樣貌,其能夠在回歸問題中得到不同的效能表現,回歸問題的模型主要分成的種類有:
至於分類問題下的模型,它的目的就是要能夠將輸入的資料區分為不同的類別 ( 分類 ),分類問題針對的是一個離散數值。
在統計學中,只能用自然數或者整數的單位計算出來值即為離散數值,就像是若要表示公司的數量或者參加會議的人數,我們不會說有 2.5 個公司或是 10.25 個人,因此真假 ( True / False )、Yes / No、物品數量、人數、性別等這種沒有連續數值關係的數值就稱為離散數值。
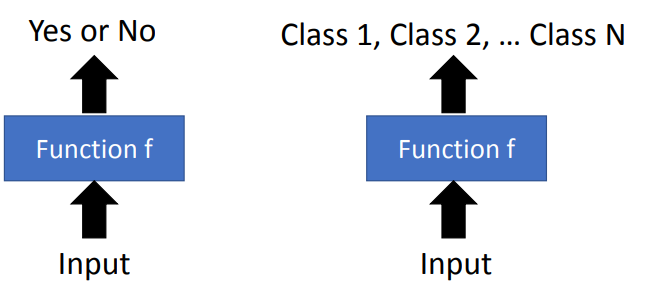
然而回歸模型和分類模型 ( 分類器 ) 所輸出的類型是不同的,回歸模型輸出的是一個數值 Scalar,而分類模型輸出的類型有分為 :
像是今天如果要模型判斷是否患有糖尿病,模型最後就會根據輸入的資料 ( 特徵 Feature ),輸出結果就會有 “ 患有糖尿病 “ 或是 “ 沒有患有糖尿病 “ 兩類,也就是模型會將輸入資料分類至 Yes 或 No 這兩類,然而並不像是 0 和 1 之間可以有無限多個數值 ( 連續關係 ), Yes 和 No 這兩個東西之間並不存在著連續的關係,因此 Yes 跟 No 就屬於離散數值,所以會說回歸問題的模型是針對一個連續數值,而分類問題為離散數值。
根據不同的模型樣貌,其能夠在分類問題中得到不同的效能表現,分類問題的模型主要分成的種類有:
我們通常會依據模型的目的不同而區分不同分類任務,當我們分類模型是用來只判斷 Yes 或 No 時,也就是只有兩類的情況下,就是在做二元的分類 ( Binary Classification ) 任務,當模型被賦予分類出更多類別 ( Class 1, Class 2 …. Class N ) 的任務時,就是在做多元的分類 ( Multi-class Classification ) 任務。
二元分類 ( Binary Classification )
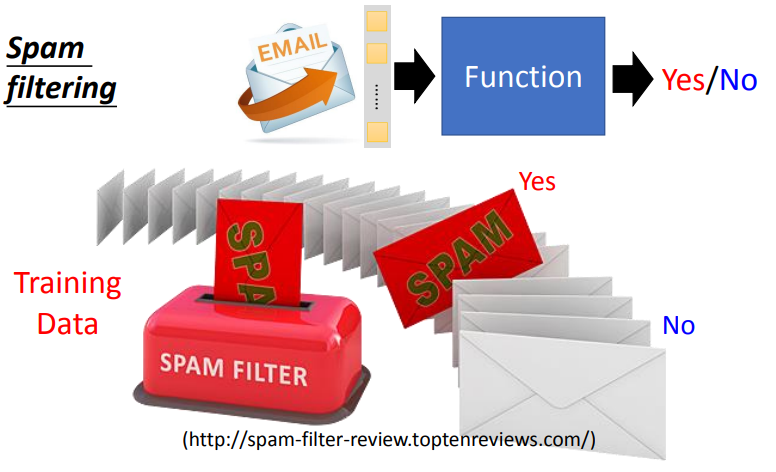
要模型輸出是或否 Yes / No,以垃圾郵件 Spam filtering 為例,就給模型一大堆的訓練資料告訴它收到的郵件哪些應該要判定為垃圾郵件 ( Spam ) 哪些不是,給模型夠多的資料去學習,它就能夠找出可以偵測垃圾郵件的方法。
多元分類 ( Muti-class Classification )
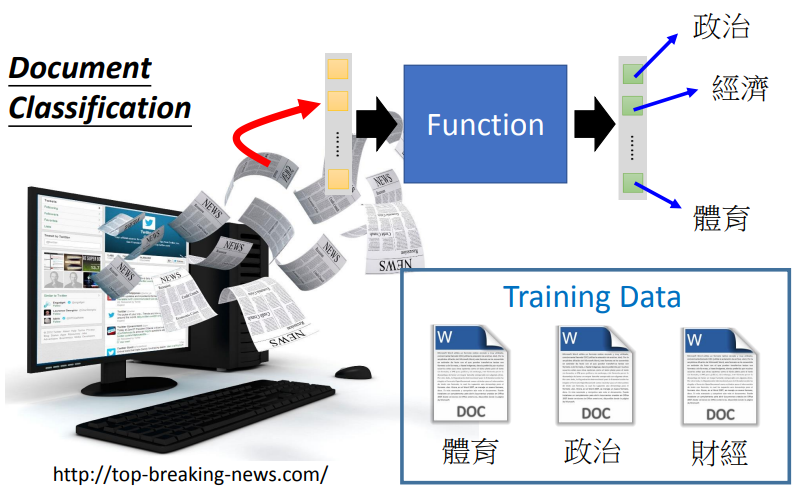
給定 N 個選項,每個選項就是一個類別,模型要從 N 個選項中選擇正確的類別,就像是希望模型能夠自動把文章做分類,而模型需要的是能夠學習出一個方法,為當輸入資料是一則文章,模型就輸出這個文章的類別,而每個類別就是一個選項,模型就是要在這些選項中完成這個選擇題,這時就需要要給模型許多訓練資料告訴它輸入哪些文章要選體育,哪些文章要選財經 ,之後給它新的文章它就可以給你正確的輸出結果。
深度學習分類 ( Classification - Deep Learning )
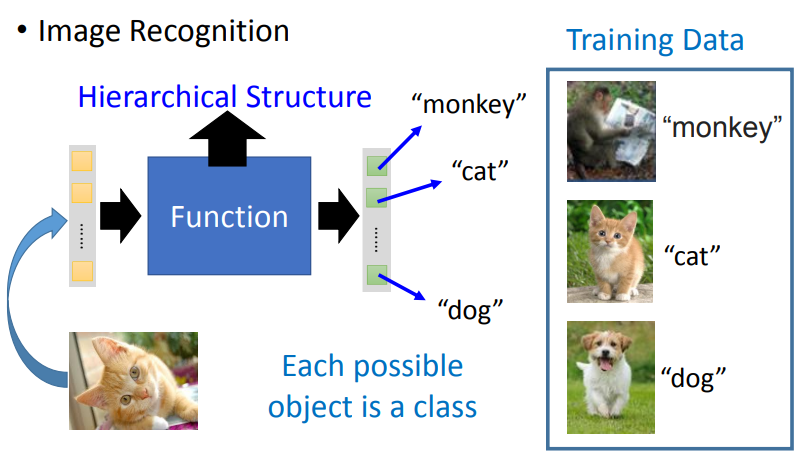
在做整個深度學習 ( Deep Learning ) 的過程中,會讓整個模型最後的輸出是非常複雜的並且非線性,以影像辨識為例,這個複雜的模型輸出它可以描述影像的像素 ( Pixel ) 與類別 ( Class ) 之間的關係,而要找出這樣的模型,就要準備許多圖片當作訓練資料讓模型去學習,而這些訓練資料就告訴了欲求的模型,它的輸入和輸出之間有什麼樣的關係,而模型的輸出就是標籤,這要找到這樣的標籤資料往往需要很大的努力而不容易。
今天我們學到了:
我們在今天了解到了回歸問題與分類問題之間的不同,以及其各種不同的模型,回歸與分類對機器學習來非常重要,我們之後也會針對這兩個部份帶著各位實作出一些模型,如果我們要讓模型能夠應付更複雜雜的問題,就需要用到神經網路 ( Neural Network , NN ) 來訓練模型,在下篇文章中,我們將踏進神經網路的世界,了解神經網路的組成與特性,那我們下篇文章見 ~
https://wiki.mbalib.com/zh-tw/离散变量
https://www.javatpoint.com/regression-vs-classification-in-machine-learning
https://www.youtube.com/watch?v=CXgbekl66jc&list=PLJV_el3uVTsPy9oCRY30oBPNLCo89yu49
台大李弘毅教授 ML Lecture 0-1: Introduction of Machine Learning

